付费问答
- 付费问答
- 技术博客
- 源码买卖
原 记录mysql5.7.30下group by 和sum函数一起使用在生产上产生的bug,差点把人搞崩溃了
版权声明:本文为博主原创文章,请尊重他人的劳动成果,转载请附上原文出处链接和本声明。
本文链接:https://www.91mszl.com/zhangwuji/article/details/1306
SELECT
date_month,
YEAR,
MONTH,
QUARTER,
vendor_no,
district_name,
company_name,
brand_name,
brand_static,
taste_name,
taste_static,
specifi_name,
specifi_static,
price_priod,
price_priod_static,
product_sys,
sum(sales_volume) AS salesVolume,
sum(sales_amount) AS salesAmount
FROM
m_sales_volume_monthly
WHERE
date_month >= '2019-10' AND date_month <= '2020-03' AND vendor_no IN ('M')
GROUP BY
date_month,
YEAR,
MONTH,
QUARTER,
vendor_no,
district_name,
company_name,
brand_name,
brand_static,
taste_name,
taste_static,
specifi_name,
specifi_static,
price_priod,
price_priod_static,
product_sys
show variables like '%iso%';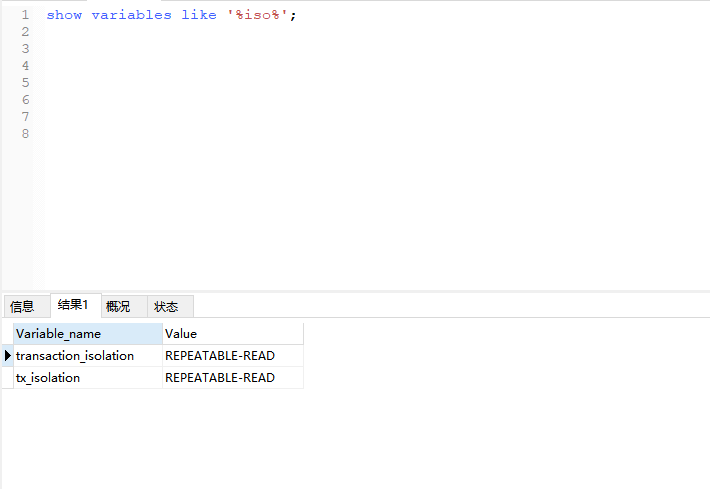
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(read uncommitted) | 可能 | 可能 | 可能 |
| 读已提交 (read committed) | 不能 | 可能 | 可能 |
| 可重复读 (repeateable read) | 不能 | 不能 | 可能 |
| 串行化 (serializable) | 不能 | 不能 | 不能 |
List<xx> biList=Collections.synchronizedList(new ArrayList<>());The server sometimes mistakenly removed a subquery with a GROUP BY when optimizing a query, even in some cases when this subquery was used by an outer select. This could occur when the subquery also used an aggregate function. (Bug #28240054)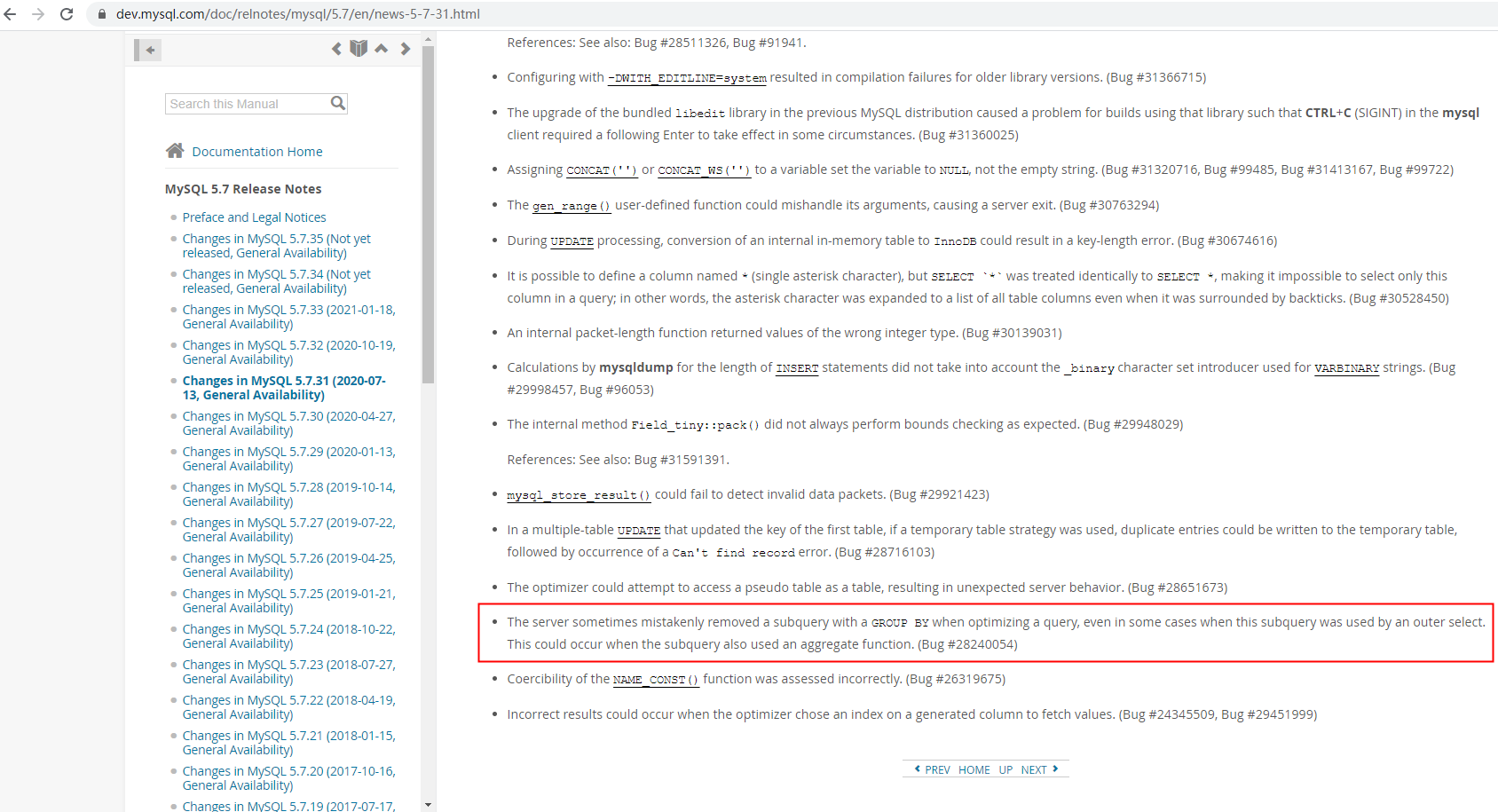
2021-03-12 20:20:21 阅读(1875)
名师出品,必属精品 https://www.91mszl.com
Copyright © 2015 - 2025. 91名师指路. All Rights Reserved. 91名师指路 版权所有 鄂ICP备2022008697号-1
 苏公网安备32058302003540
苏公网安备32058302003540
